|
查看: 676|回复: 47
|
中国大模型DeepSeek正在让硅谷陷入恐慌
 [复制链接]
[复制链接]
|
|
|
中国大模型DeepSeek正在让硅谷陷入恐慌
凤凰网科技讯 1月24日,CNBC发文称,DeepSeek R1,因其性能超越美国顶尖同类模型,且构建成本更低、使用的芯片算力也较弱,引发了硅谷的恐慌。
CNBC表示,DeepSeek R1使用英伟达性能稍逊的H800芯片,仅用两个月时间、不到600万美元就构建完成了这个模型。
在一系列第三方基准测试中,从复杂问题解决到数学和编码等方面,DeepSeek的模型在准确性上超越了Meta的Llama 3.1、OpenAI的GPT-4o以及Anthropic的Claude Sonnet 3.5。
这引发了美方担忧:美国在人工智能领域的全球领先地位是否正在缩小?大型科技公司在构建人工智能模型和数据中心方面的巨额投入是否值得?
标杆资本合伙人切坦・普塔贡塔表示:“DeepSeek采用一种名为知识蒸馏的过程,来打造一个非常出色的大型模型。基本上,就是利用一个非常大的模型,帮助小模型在你期望的领域变得智能。这实际上非常具有成本效益。”
微软首席执行官萨蒂亚・纳德拉周三在瑞士达沃斯世界经济论坛上表示:“看到DeepSeek的新模型,真的令人印象非常深刻。他们切实有效地开发出了一款开源模型,在推理计算方面表现出色,且超级计算效率极高。”
“我们必须非常、非常认真地对待中国的这些进展。”纳德拉说。” |
|
|
|
|
|
|
|
|
|
|
|
 发表于 26-1-2025 02:33 PM
来自手机
|
显示全部楼层
发表于 26-1-2025 02:33 PM
来自手机
|
显示全部楼层
本帖最后由 Mr.Bean 于 26-1-2025 02:35 PM 编辑
磊哥的节目也有介绍, 美国AI行业崩塌了! 中国deepseek R1碾压chatgpt! |
|
|
|
|
|
|
|
|
|
|
|
发表于 26-1-2025 02:51 PM
|
显示全部楼层
|
|
|
|
|
|
|
|
|
|
|
发表于 26-1-2025 02:54 PM
|
显示全部楼层
中国的数学可以说是世界第一的,更何况是卷着进去大学学府。。。
没有三两两怎样折服世界。 |
|
|
|
|
|
|
|
|
|
|
|
发表于 26-1-2025 02:56 PM
来自手机
|
显示全部楼层
JamesWongSC 发表于 26-1-2025 02:51 PM
对了, 就是这个影片, 某个ngong居美吹心里难受极了! 他正在思考怎样否定反驳这件事, 怎样帮美国洋大人洗地挽面子, 他现在正在看帖的。 |
|
|
|
|
|
|
|
|
|
|
|
发表于 26-1-2025 03:04 PM
|
显示全部楼层
|
|
|
|
|
|
|
|
|
|
|

楼主 |
发表于 26-1-2025 05:35 PM
|
显示全部楼层
国产AI大模型DeepSeek冲破封锁全球刷屏,成本仅为GPT的1/20
近日,量化巨头幻方量化的子公司深度求索(DeepSeek)发布了全新系列模型DeepSeek-V3,并同步开源。这一事件迅速引爆AI圈,DeepSeek-V3不仅霸榜开源模型,更在性能上与全球顶尖闭源模型GPT-4o和Claude-3.5-Sonnet不相上下。
更令人瞩目的是,该模型的训练成本仅约558万美元,仅为GPT-4o的二十分之一,资源运用效率极高。国外独立评测机构Artificial Analysis测试评价其“超越了迄今为止所有开源模型”。
与此同时,在2024年的年末,“雷军千万年薪挖角95后AI‘天才少女’罗福莉”的词条刷屏社交网络。罗福莉是DeepSeek-V2的关键开发者之一,据证券时报报道,雷军欲让其领导小米AI大模型团队。国产大模型DeepSeek一定程度也因此走向大众视野。
DeepSeek-V3的成功,不仅是中国AI技术的一次重大突破,更是全球AI格局重塑的重要标志。
“来自东方的神秘力量”
DeepSeek再进化
2024年12月26日,深度求索官方微信公众号推文称,旗下全新系列模型DeepSeek-V3首个版本上线并同步开源。该国产大模型性能对齐海外领军闭源模型,多项评测成绩超越了Qwen2.5-72B和Llama-3.1-405B等其他开源模型,并在性能上和世界顶尖的闭源模型GPT-4o以及Claude-3.5-Sonnet不分伯仲。
在百科知识、长文本、代码、数学及中文能力上的表现,DeepSeek-V3超越其他模型,尤其是在数学上,在美国数学竞赛(AIME 2024, MATH)和全国高中数学联赛(CNMO 2024)上,DeepSeek-V3大幅超过了所有开源闭源模型。
更重要的是,深度求索使用英伟达H800 GPU在短短两个月内就训练出了DeepSeek-V3,仅花费了约558万美元。其训练费用相比GPT-4o等大模型要少得多。Open AI CEO山姆·奥特曼曾表示,GPT-4o的训练成本大约1亿美元,未来训练大模型的成本将高于10亿美元。尚未完成训练的GPT-5大模型,为时约半年的一轮训练就消耗了大约5亿美元。
消息一出,引发了海外AI圈热议。Open AI创始成员Karpathy甚至对此称赞道:“DeepSeek-V3让在有限算力预算上进行模型预训练这件事变得容易。”
深度求索被硅谷誉为“来自东方的神秘力量”,在2024年5月6日发布由AI“天才少女”罗福莉参与研发的DeepSeek-V2开源MoE模型时,就以其高效性能在全球AI界掀起了一波热度。
而其API接口价格与同类产品相比断崖式定为每百万tokens输入1元、输出2元(32K上下文),仅为GPT-4 Turbo的近百分之一。
花小钱办大事,“四两拨千斤”
低成本高效能的创新路径
DeepSeek做到了花小钱办大事,通过更先进的MoE架构、多技术融合优化、FP8混合精度训练框架等技术,以及与开源社区合作的方法,在成本较低的情况下,就训练出文字生成和逻辑推理能力不输乃至领先主流AI大模型DeepSeek-V3。
DeepSeek-V3的成功离不开其独特的技术创新。首先,其采用的混合专家(MoE)架构通过稀疏激活机制,仅激活37亿参数,显著降低了计算量,同时提升了模型的处理能力。其次,DeepSeek团队开发的多头潜在注意力(MLA)机制和FP8混合精度训练框架,进一步优化了模型的训练效率和生成速度,使其生成速度从每秒20个token提升至60个token(token 是计算机科学中的信息或价值的基本单位,用于表示、传输或存储数据)。此外,DualPipe算法的引入,有效降低了跨节点通信的开销,使得训练成本大幅降低。
这些技术创新不仅让DeepSeek-V3在性能上比肩顶尖闭源模型,更在成本控制上实现了突破,展现了“四两拨千斤”的技术实力。
训练成本高昂、竞争愈发激烈已成趋势,如何开源与节流已成全球AI公司必须思考的难题,DeepSeek这种低成本高效能的模式,为全球AI大模型的开发提供了新的思路。
突破封锁:硬件限制催生软件创新
DeepSeek-V3的成功,某种程度上是中国在AI领域突破外国技术封锁的缩影。2022年,美国对中国实施芯片出口限制,旨在遏制中国在AI领域的发展。然而,DeepSeek团队通过软件层面的创新,充分利用性能受限的H800 GPU,实现了训练效率的显著提升。
例如,FP8混合精度训练框架的运用,不仅降低了内存占用,还加快了计算速度,使得在硬件性能受限的情况下,依然能够高效完成大规模模型的训练。这种“硬件不足,软件补足”的策略,不仅让DeepSeek-V3在技术上实现了突破,更在某种程度上打破了美国对中国的技术封锁。
正如一位硅谷AI工程师所言:“DeepSeek的成功证明,创新并不一定依赖于最先进的硬件,而是可以通过聪明的工程设计和高效的训练方法实现。”这种由需求驱动的创新,不仅为中国AI技术的发展注入了新的活力,也为全球AI领域提供了新的可能性。 |
|
|
|
|
|
|
|
|
|
|
|
发表于 26-1-2025 06:26 PM
|
显示全部楼层
|
|
|
|
|
|
|
|
|
|
|
发表于 26-1-2025 06:30 PM
|
显示全部楼层
|
|
|
|
|
|
|
|
|
|
|
发表于 26-1-2025 06:32 PM
来自手机
|
显示全部楼层
lcw9988 发表于 26-1-2025 06:26 PM
笑死人, 又拿没读书的小混混视频当真 ! 就是让悲慘没钱过年的韭菜看视频自嗨打飞机
第一, 从代码看 deeps ...
说那么多也没用, 看dalap的标题就完事了, deepseek让硅谷陷入恐慌, 而你就在这里用一些不知所谓的资料在粉饰太平! 这些东西你拿去对洋主人说好了! 👎👎👎👎 |
|
|
|
|
|
|
|
|
|
|
|
发表于 26-1-2025 06:38 PM
|
显示全部楼层
|
|
|
|
|
|
|
|
|
|
|
发表于 26-1-2025 06:42 PM
|
显示全部楼层
本帖最后由 lcw9988 于 26-1-2025 06:45 PM 编辑
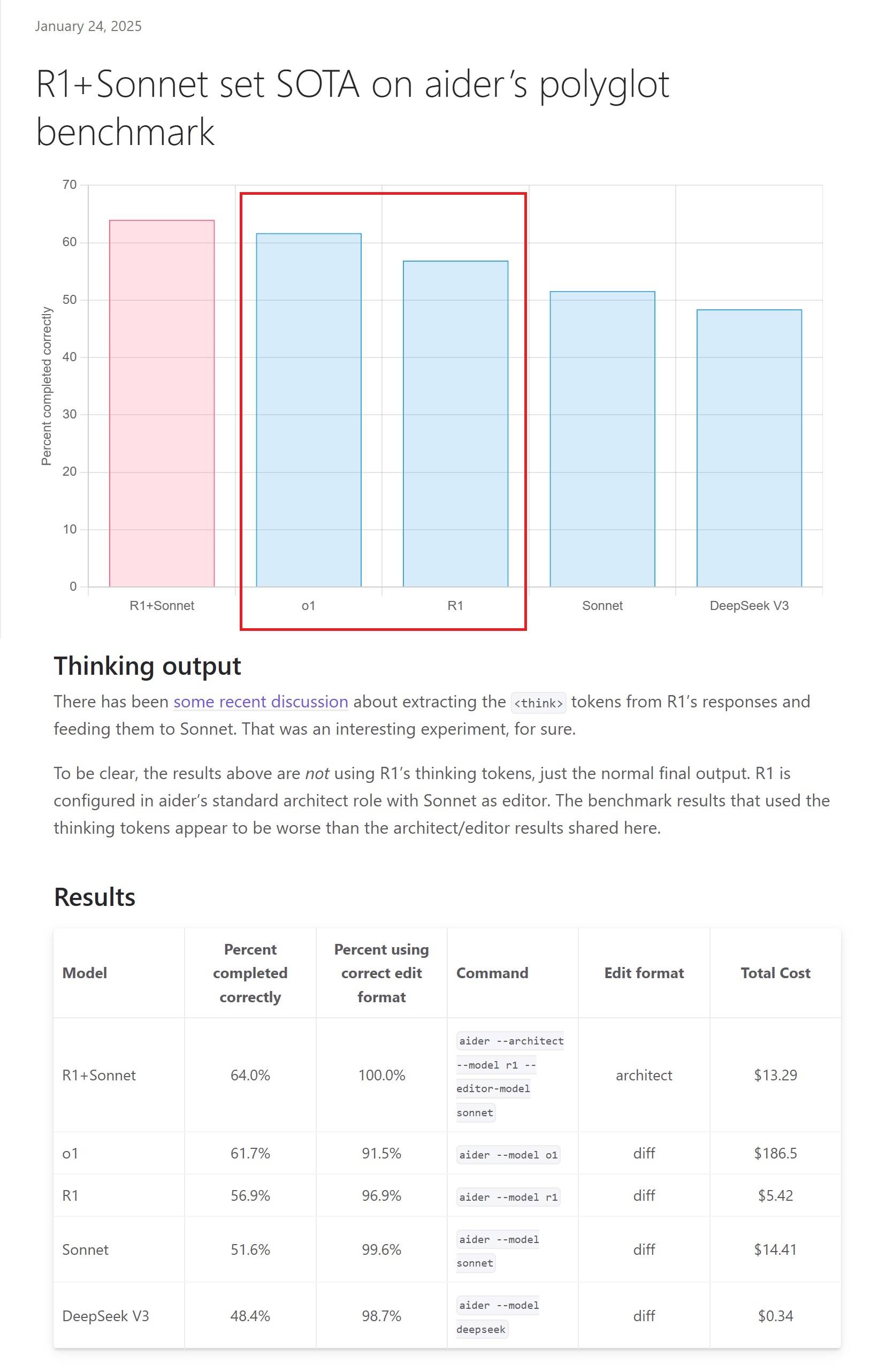
说那么多也没用, 一切以benchmark基准说了算, 嘴炮没有用 !
deepseek让硅谷陷入恐慌? Meta, Nvidia 股价大跌了? 恐慌只是小粉红无中生有而己 !
人家只是说deepseek性能不错接近 GPT o1 !
|
评分
-
查看全部评分
|
|
|
|
|
|
|
|
|
|
|
发表于 26-1-2025 07:01 PM
来自手机
|
显示全部楼层
lcw9988 发表于 26-1-2025 06:42 PM
说那么多也没用, 一切以benchmark基准说了算, 嘴炮没有用 !
deepseek让硅谷陷入恐慌? Meta, Nvidia 股价 ...
文章一开头就说了, CNBC发文称deepseek超越美国顶尖同类产品! |
|
|
|
|
|
|
|
|
|
|
|
发表于 26-1-2025 07:01 PM
|
显示全部楼层
一点AI知识都没有, 只有一项Data Analysis超越 GPT-o1就吹成碾压GPT, 无知只会让人笑话啦 !
|
|
|
|
|
|
|
|
|
|
|
|
发表于 26-1-2025 07:02 PM
|
显示全部楼层
一点AI知识都没有, 死拗没用的, benchmark说了算, 只有一项Data Analysis超越 GPT-o1就吹成碾压GPT, 无知只会让人笑话啦, 小粉红又变落水狗了. oh yeah !

|
|
|
|
|
|
|
|
|
|
|
|
发表于 26-1-2025 07:05 PM
|
显示全部楼层
|
|
|
|
|
|
|
|
|
|
|
发表于 26-1-2025 07:08 PM
来自手机
|
显示全部楼层
lcw9988 发表于 26-1-2025 07:02 PM
一点AI知识都没有, 死拗没用的, benchmark说了算, 只有一项Data Analysis超越 GPT-o1就吹成碾压GPT, 无知 ...
你能想到的难道人家就没想到? 要不然人家也不会随便发文说超越了! 你玻璃心死拗也是你家的事! 看磊哥的影片标题都打败你这个嘴炮了! 你就拿你上面那些不知所谓又乱七八糟的资料去安慰洋大人好了! 要不找磊哥辩论! 你辩得赢他就算你牛! |
|
|
|
|
|
|
|
|
|
|
|
发表于 26-1-2025 07:08 PM
|
显示全部楼层
|
|
|
|
|
|
|
|
|
|
|
发表于 26-1-2025 07:09 PM
|
显示全部楼层
|
|
|
|
|
|
|
|
|
|
|
发表于 26-1-2025 07:11 PM
|
显示全部楼层
AI 大佬 Yann LeCun说的

|
|
|
|
|
|
|
|
|
|
| |
 本周最热论坛帖子 本周最热论坛帖子
|









 变色卡
变色卡 千斤顶
千斤顶




 1859
1859  69
69